Matrix3D: nova IA da Apple simplifica a geração de modelos 3D
A equipe de Pesquisa em Aprendizado de Máquina da Apple, em parceria com pesquisadores da Universidade de Nanquim e da Universidade de Ciência e Tecnologia de Hong Kong (HKUST), publicou um artigo científico apresentando um novo modelo de IA chamado Matrix3D.
Chamado de Large Photogrammetry Model (ou Grande Modelo de Fotogrametria), ele é capaz de utilizar apenas algumas imagens 2D para reconstruir seus elementos, como cenas e objetos, em modelos 3D detalhados.
Ele utiliza da já conhecida técnica de fotogrametria para fazer medições das imagens 2D e reconstruir seus modelos em 3D. O diferencial aqui é que, antes, esse processo exigia diversas imagens tiradas de diferentes ângulos e inúmeros algoritmos para calcular etapas como estimativa de posição da câmera e previsão de profundidade — o que frequentemente causava erros e ineficiências na hora de criar os modelos. Mas o Matrix3D propôs uma solução criativa e inovadora para esses problemas.
Para driblar a necessidade de tirar várias fotos e de utilizar modelos separados em cada etapa da reconstrução, o modelo unifica o processo e resolve os dois problemas de uma vez só. Ele utiliza poucas imagens de entrada para estimar parâmetros da câmera (como posição e distância focal), bem como dados de profundidade, e os processa como um todo, simplificando o fluxo de trabalho e melhorando a precisão dos resultados.
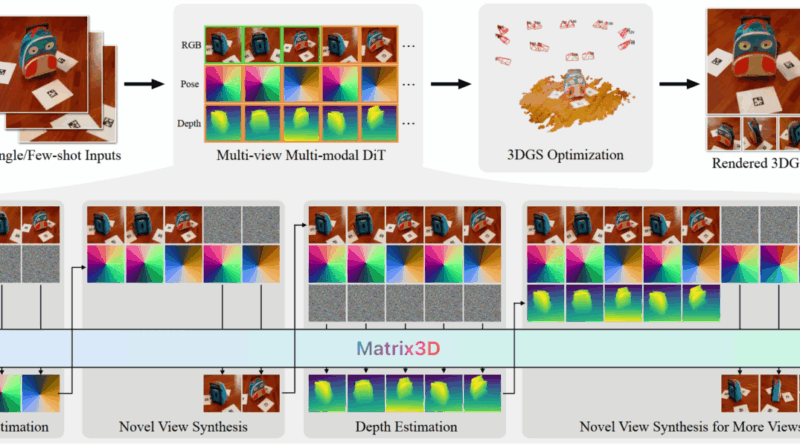
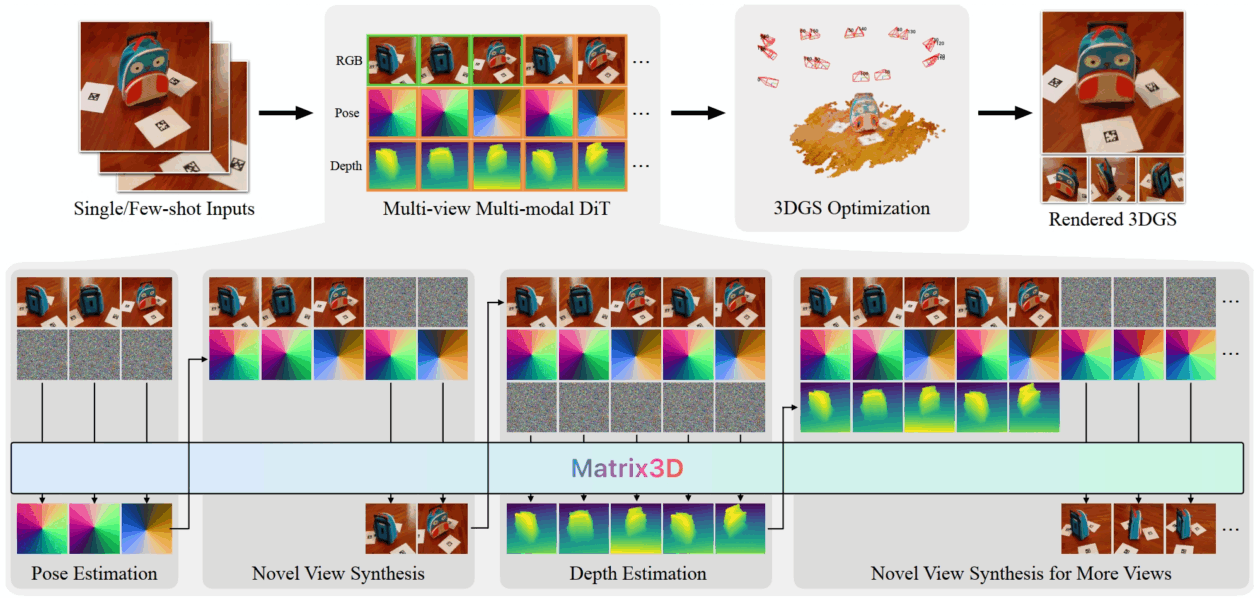
Apresentamos o Matrix3D, um modelo unificado que realiza diversas subtarefas de fotogrametria, incluindo estimativa de pose, predição de profundidade e síntese de novas vistas, utilizando apenas o mesmo modelo. O Matrix3D utiliza um transformador de difusão multimodal (DiT) para integrar transformações em diversas modalidades, como imagens, parâmetros de câmera e mapas de profundidade. A chave para o treinamento multimodal em larga escala do Matrix3D reside na incorporação de uma estratégia de aprendizado mascarado. Isso permite o treinamento de modelos de modalidade completa mesmo com dados parcialmente completos, como dados bimodais de pares imagem-pose e imagem-profundidade, aumentando significativamente o conjunto de dados de treinamento disponíveis. O Matrix3D demonstra desempenho de ponta em tarefas de estimativa de pose e síntese de novas vistas. Além disso, oferece controle refinado por meio de interações em várias rodadas, tornando-se uma ferramenta inovadora para a criação de conteúdo 3D.
O Matrix3D se alimenta de um sistema de IA generativa baseado em transformadores de difusão, similar aos modelos utilizados no DALL-E e Chat GPT. Ele foi treinado por uma técnica denominada aprendizado mascarado, na qual partes dos dados de entrada são ocultadas aleatoriamente para que o modelo aprenda a “preencher as lacunas” e prever as informações ausentes.
Essa estratégia é semelhante à utilizada nos primeiros sistemas de IA baseados em Transformer, que ajudaram a criar as primeiras versões do ChatGPT, e foi fundamental para que o Matrix3D treinasse de forma eficaz, mesmo com conjuntos de dados menores ou incompletos, expandindo significativamente a gama de amostras de treinamento utilizáveis.
Como resultado, o modelo é capaz de criar reconstruções 3D detalhadas de objetos e ambientes com apenas duas ou três imagens de entrada, o que pode oferecer aplicações imersivas interessantes ao Apple Vision Pro.
Os pesquisadores publicaram o artigo sobre o Matrix3D no arXiv e disponibilizaram seu código-fonte no GitHub. Além disso, criaram um site contendo vídeos de demonstração e reconstruções 3D interativas de alguns objetos e ambientes.
via 9to5Mac